Wo endet KI-Komfort und wo beginnt echtes Datenrisiko?
KI verspricht Produktivität.
Was sie oft liefert, ist ein neuer Datenabflusskanal.
Nicht aus böser Absicht – sondern aus Bequemlichkeit.
Ein Prompt ist schnell geschrieben.
Und genauso schnell verlassen interne Informationen das Unternehmen.
Die unbequeme Wahrheit:
Die meisten Firmen wissen nicht, was ihre Mitarbeiter täglich an KI-Anbieter senden.
„Wir vertrauen unseren Mitarbeitenden“ ist kein Sicherheitskonzept
In der Praxis sieht es so aus:
- Projekt- und Kundennamen landen im Prompt
- Interne Prozesse werden „kurz erklärt“
- Fehlermeldungen enthalten Systemdetails
- Vertrags- oder Personendaten werden „zur Analyse“ kopiert
Nicht, weil jemand fahrlässig handelt.
Sondern weil KI reibungslos funktioniert.
Genau das ist das Problem.
Die eigentliche Frage lautet nicht: Welches Modell nutzen wir?
Die relevante Frage ist:
Welche Informationen dürfen unser Unternehmen überhaupt verlassen?
Und noch wichtiger:
Wer überprüft das – in Echtzeit, automatisiert und lückenlos?
Antwort in vielen Unternehmen:
Niemand. Oder: ein internes Regelwerk, das technisch nicht durchsetzbar ist.
Warum klassische KI-Integrationen hier versagen
Direkte API-Anbindungen bieten:
- keine inhaltliche Kontrolle
- keine Kontextprüfung
- keine zentrale Filterlogik
- keine Beweisbarkeit im Auditfall
Der Provider bekommt den Prompt so, wie er geschrieben wurde.
Alles andere ist Hoffnung.
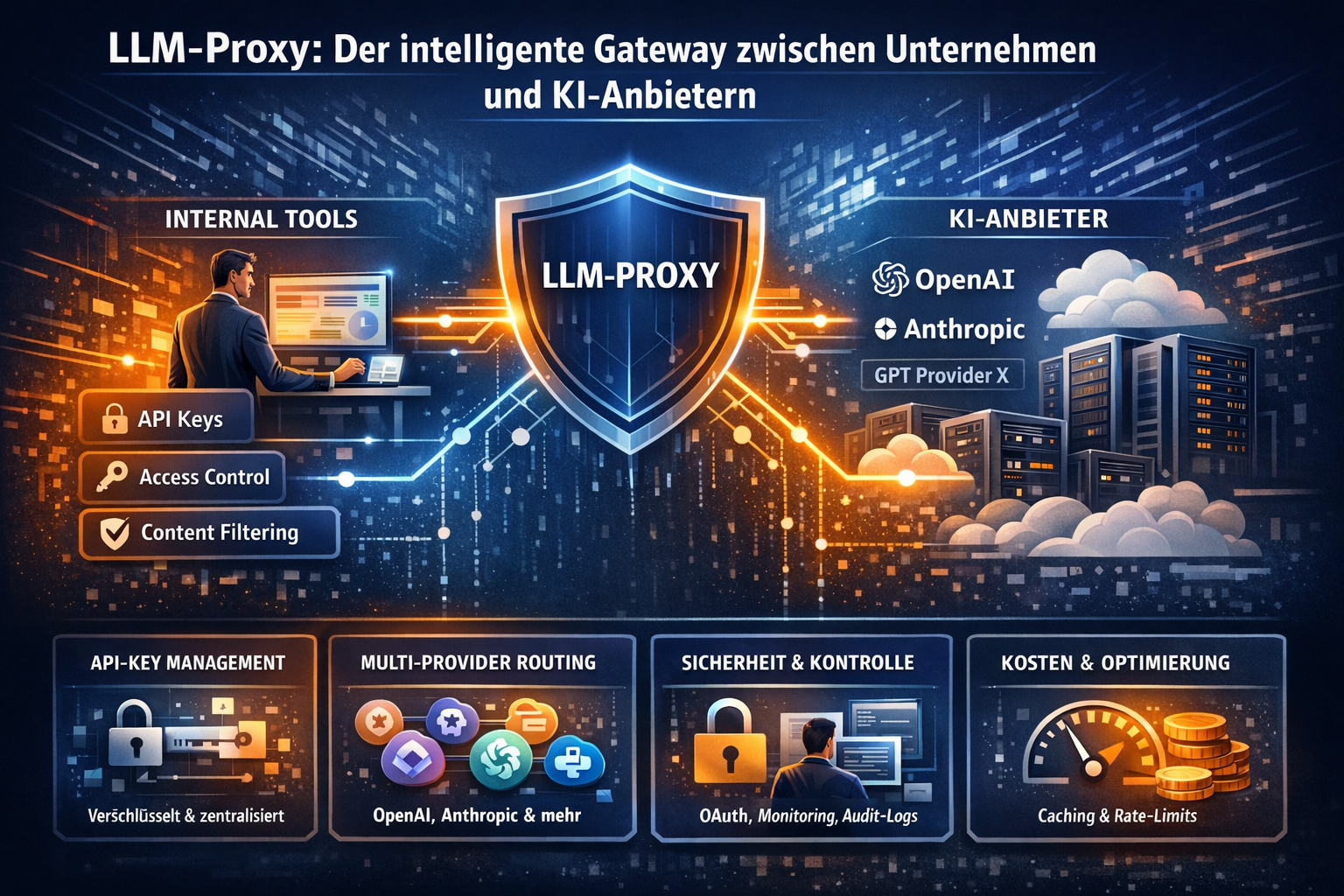
Was ein LLM-Proxy wirklich leisten muss – und was nicht
Ein LLM-Proxy ist kein Marketing-Feature.
Er ist eine letzte technische Barriere vor dem externen System.
Und genau dort entscheidet sich, ob ein Unternehmen Kontrolle hat – oder nur glaubt, sie zu haben.
Die entscheidende Fähigkeit: Inhalte vor dem Modell zu kontrollieren
LLM-Proxy setzt vor der Weiterleitung an:
- Der vollständige Prompt wird abgefangen
- Inhalte werden analysiert
- Regeln werden angewendet
- Erst dann geht die Anfrage weiter – oder eben nicht
Das ist der kritische Punkt.
Nicht Logging.
Nicht Kostenkontrolle.
Inhaltskontrolle.
„Confidential“ ist kein Schlagwort, sondern ein Regelwerk
Was vertraulich ist, weiss jedes Unternehmen selbst:
- Kundennamen
- Projektnamen
- interne Produktnamen
- Domains
- Personendaten
- Vertragsbegriffe
- regulatorisch relevante Keywords
LLM-Proxy erlaubt, genau diese Dinge explizit zu definieren:
- Wortlisten
- Phrasen
- Regex-Regeln
- Kategorien mit Prioritäten
- Ersetzen, Maskieren oder Blockieren
Das Ziel ist nicht Überwachung.
Das Ziel ist Prävention.
Der entscheidende Unterschied: Filtern statt Reagieren
Viele Firmen verlassen sich auf:
- Anbieter-Richtlinien
- „Wir speichern keine Daten“-Versprechen
- Schulungen
Das alles passiert nachdem die Daten das Haus verlassen haben.
Ein Proxy dreht das Modell um:
Was nicht raus darf, verlässt das Unternehmen gar nicht erst.
Kein Logging-Drama.
Kein juristisches Nachspiel.
Kein „hätten wir wissen müssen“.
Kritische Grenze: Ein Proxy ersetzt kein Denken
So ehrlich muss man sein:
- Ein Proxy versteht keine Geschäftslogik
- Er erkennt keine impliziten Bedeutungen
- Er ersetzt keine Klassifizierungsstrategie
Aber:
Er erzwingt technische Disziplin.
Und Disziplin schlägt Vertrauen – immer.
Wann ein LLM-Proxy unverzichtbar wird
- Sobald mehr als ein Team KI nutzt
- Sobald Kundendaten im Spiel sind
- Sobald Regulierung greift
- Sobald „mal schnell ChatGPT fragen“ zum Alltag gehört
Ab diesem Punkt ist „direkt integrieren“ keine Option mehr, sondern ein Risiko.
Fazit: Kontrolle beginnt vor dem Prompt
Die wichtigste Eigenschaft eines LLM-Systems ist nicht das Modell.
Sondern die Frage:
Was darf dieses Modell überhaupt zu sehen bekommen?
LLM-Proxy zwingt Unternehmen, diese Frage technisch zu beantworten – nicht kulturell, nicht politisch, sondern architektonisch.
Alles andere ist Hoffnung.
Und Hoffnung ist kein Sicherheitskonzept.
Wenn du willst, kann ich als nächsten Schritt:
- eine radikal kurze Executive-Version schreiben
- ein „Warum wir keinen direkten KI-Zugriff erlauben“-Policy-Dokument formulieren
- oder eine technische Deep-Dive-Seite nur zum Content-Filtering ausarbeiten